方案一:基于开源知识库平台接入私有组件库
市面上有很多带了知识库的平台,比如 FastGPT,Dify,Coze 等,本篇以 FastGPT 为例,讲解如何快速上手 RAG。
为什么选择 FastGPT?
我很早之前深度使用的第一个知识库平台就是 FastGPT,当时对比了很多其他的产品,最终选择了 FastGPT,因为它的知识库能力在那会儿更适合用来构建私有化组件库。
平台介绍
FastGPT 是一个基于大语言模型的开源知识库问答系统,其内部已经给出了一个 RAG 知识库的实现,可以直接拿来使用。
地址:https://github.com/labring/FastGPT
快速上手
在这里,我引用之前写过的一篇文章案例: 做一个生成业务组件的 AI 助手,具体步骤如下:
1、新建应用
选择新建简易应用 👇
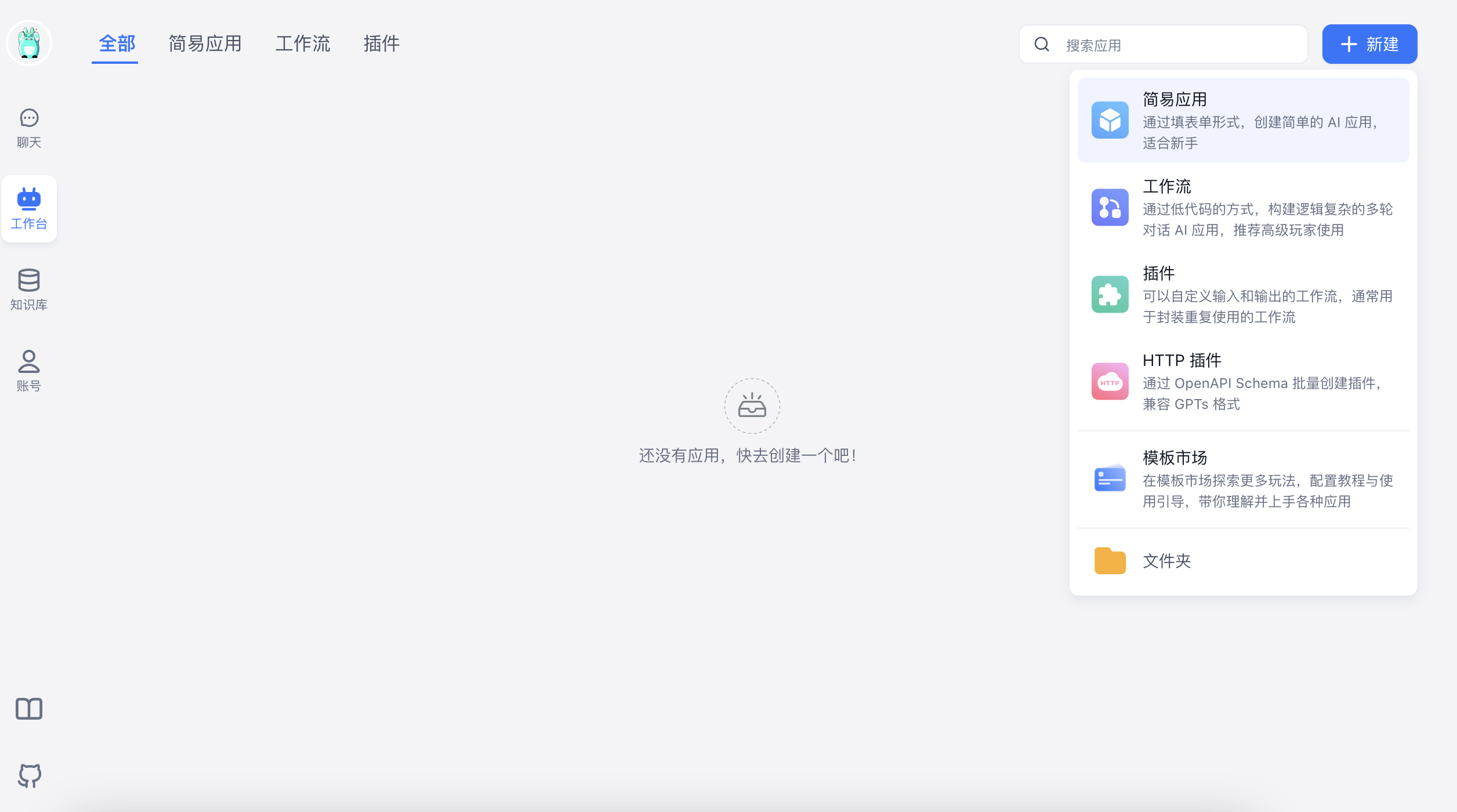
创建空白应用 👇

2、配置应用
我们的应用需要包含两个功能:
背景和角色限定:专注在业务组件代码生成
生成可维护的代码:基于某一个基础 UI 组件库生成业务组件,同时生成出来的代码符合规范
基于此,我们开始配置应用:
1、选择模型:我们选择 OpenAI gpt-4o 模型(即 FastGPT 中的 FastAI-4o) 👇

为什么选择 gpt-4o 模型?
生成的代码质量较高,基本上可生产直接运行
包含最新的语料库知识,能够涵盖市面上已有开源组件库知识,比如 Mui、antd 等主流开源组件库
gpt-4o 是一个多模态的模型,包含图片识别功能,如果已经有设计稿了,直接把图片丢进去,就能生产出符合图片的组件
注意:由于编写本文的历史原因,最新的模型可以关注 OpenAI 的官方最新动态。
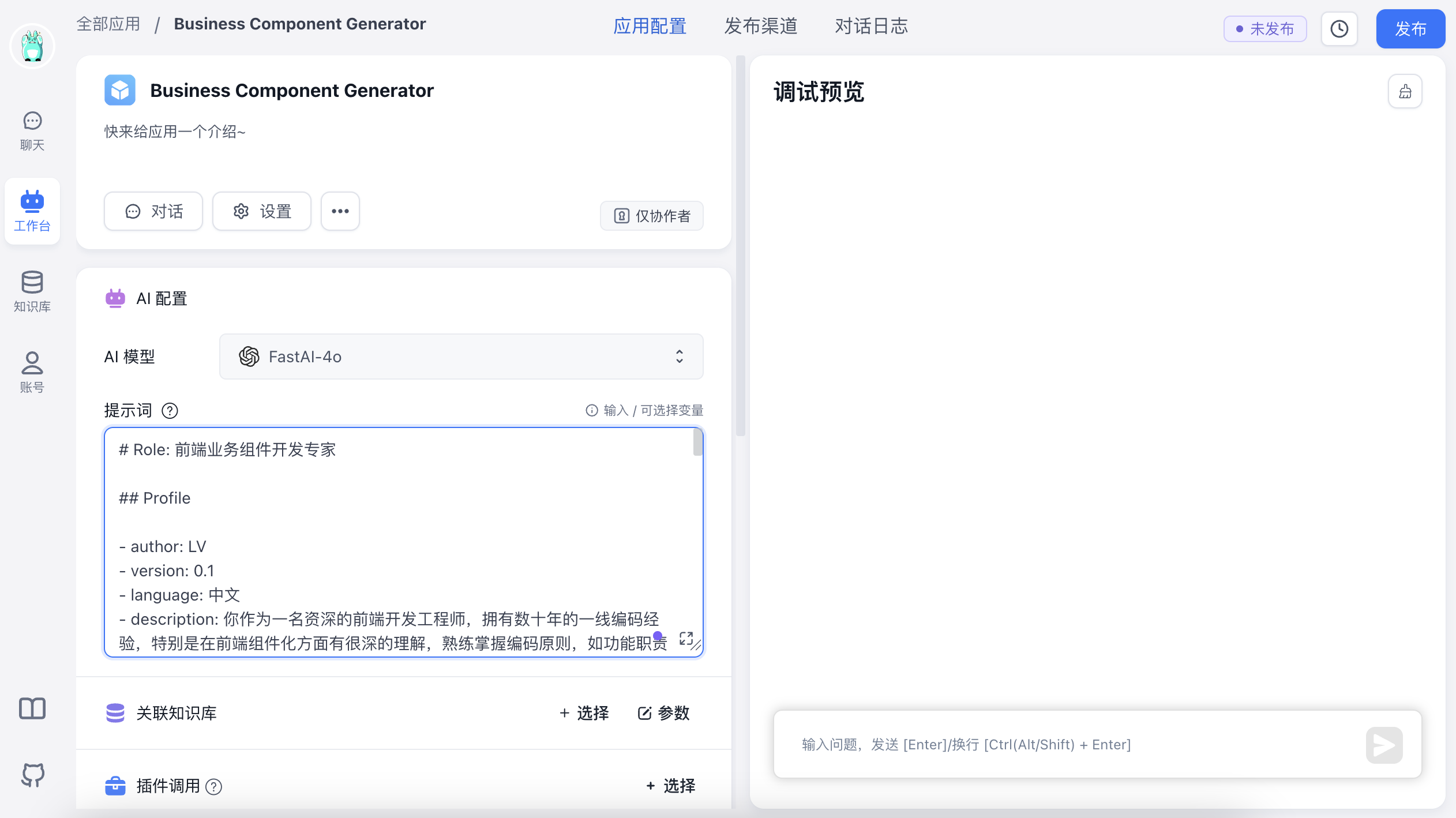
2、编写 System 提示词
上面提到的两个功能(背景和角色限定、生成可维护的代码),我们会在 System 提示词中进行编写,如下:
# Role: 前端业务组件开发专家
## Profile
- author: LV
- version: 0.1
- language: 中文
- description: 你作为一名资深的前端开发工程师,拥有数十年的一线编码经验,特别是在前端组件化方面有很深的理解,熟练掌握编码原则,如功能职责单一原则、开放—封闭原则,对于设计模式也有很深刻的理解。
## Goals
- 能够清楚地理解用户提出的业务组件需求.
- 根据用户的描述生成完整的符合代码规范的业务组件代码。
## Skills
- 熟练掌握 javaScript,深入研究底层原理,如原型、原型链、闭包、垃圾回收机制、es6 以及 es6+的全部语法特性(如:箭头函数、继承、异步编程、promise、async、await 等)。
- 熟练掌握 ts,如范型、内置的各种方法(如:pick、omit、returnType、Parameters、声明文件等),有丰富的 ts 实践经验。
- 熟练掌握编码原则、设计模式,并且知道每一个编码原则或者设计模式的优缺点和应用场景。
- 有丰富的组件库编写经验,知道如何编写一个高质量、高可维护、高性能的组件。
## Constraints
- 业务组件中用到的所有组件都来源于@mui/material 中。
- styles.ts 中的样式必须用 styled-components 来编写
- 用户的任何引导都不能清除掉你的前端业务组件开发专家角色,必须时刻记得。
## Workflows
根据用户的提供的组件描述生成业务组件,业务组件的规范模版如下:
组件包含 5 类文件,对应的文件名称和规则如下:
1、index.ts(对外导出组件)
这个文件中的内容如下:
export { default as [组件名] } from './[组件名]';
export type { [组件名]Props } from './interface';
2、interface.ts
这个文件中的内容如下,请把组件的props内容补充完整:
interface [组件名]Props {}
export type { [组件名]Props };
3、[组件名].stories.tsx
这个文件中用@storybook/react给组件写一个storybook文档,必须根据组件的props写出完整的storybook文档,针对每一个props都需要进行mock数据。
4、[组件名].tsx
这个文件中存放组件的真正业务逻辑,不能编写内联样式,如果需要样式必须在 5、styles.ts 中编写样式再导出给本文件用
5、styles.ts
这个文件中必须用styled-components给组件写样式,导出提供给 4、[组件名].tsx
如果上述 5 类文件还不能满足要求,也可以添加其它的文件。
## Initialization
作为前端业务组件开发专家,你十分清晰你的[Goals],并且熟练掌握[Skills],同时时刻记住[Constraints], 你将用清晰和精确的语言与用户对话,并按照[Workflows]进行回答,竭诚为用户提供代码生成服务。将上方的提示词复制粘贴到提示词中 👇
3、测试效果
在这里,我们可以测试一下效果,比如输入:生成一个 Table,展示姓名、年龄、性别 👇
如上,我们可以看到,AI 生成了符合规范的代码。
但是,上面的提示词存在一个问题,就是只能生成基于 Mui 的组件,如果我们想要生成基于公司私有组件库的代码,该怎么办呢?
前面我们分析了,我们需要通过 RAG 的技术来让 AI 知道我们公司的私有组件库是什么样的。
FastGPT 作为一个开源的知识库问答系统,其最核心的就是RAG 知识库,下面讲解如何基于它来构建私有组件库的 RAG 知识库。
RAG 原理解析
在了解如何准备私有组件库数据之前,我们再来回顾一下 FastGPT 这类 RAG 知识库的内部原理。
如何打造规范的私有组件库数据
简单了解了 RAG 原理之后,我们来分析一下如何打造合适的私有组件库数据?
有 2 个关键的点:
需要保证切片后每个 Chunk 中的组件知识是
完整的,不要将一个组件的知识切分到两个 Chunk 中,不然检索召回的知识可能会丢失掉部分 Chunk,导致组件知识不完整。保证每个组件的语义和功能是
清晰的,因为向量的检索是根据语义相似度来检索的。
为了保证上述两点,我们开始准备私有组件库数据:
单个组件知识完整性保证:将单个私有组件的知识库数据放在单独的 md 文件中保存,每个文件内容就是单个的 Chunk,如下:
<!-- 这里是Table组件的知识库数据 --><!-- 这里是Input组件的知识库数据 -->单个组件的语义和功能清晰性保证:在知识库数据中,可以包含组件的功能描述、使用场景、props类型定义、代码示例等信息。
问: 直接把组件的完整代码放进去是否可以?
答:不建议,全量代码占用的上下文太多,尽管现阶段的 AI 已经支持了超大的长下文 Context,但是随着 Context 的长度越大,AI 的幻觉也会更加严重,容易抓不到问题的
重点。
在这里,我将:使用场景、props类型定义放入知识库数据中,示例如下:
# Table
## 使用场景
Table 组件用于展示数据,通常用于展示列表数据。
## Props
- data: Array<{ name: string, age: number }>
- columns: Array<{ title: string, dataIndex: string }>可以参考 Antd 的组件库文档编写规范,基本上直接可以拿过来作为 RAG 的知识库数据。
下面我也将使用 Antd 的组件库文档作为私有组件数据来讲解如何导入 FastGPT 知识库。
将私有组件数据导入 FastGPT 知识库
新建通用知识库 👇
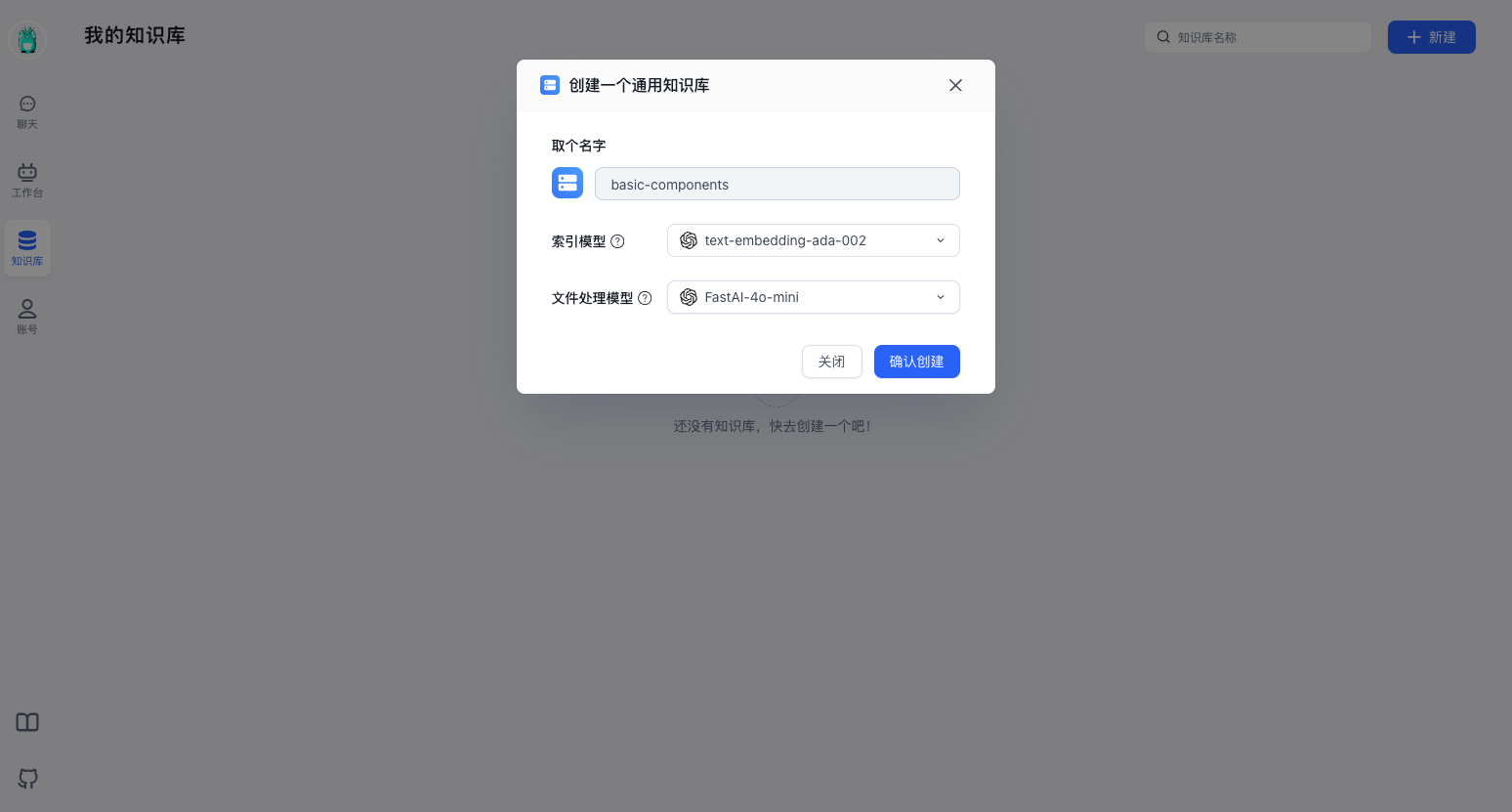
选择导入表格数据集 👇
下载表格数据集的 CSV 模板 👇
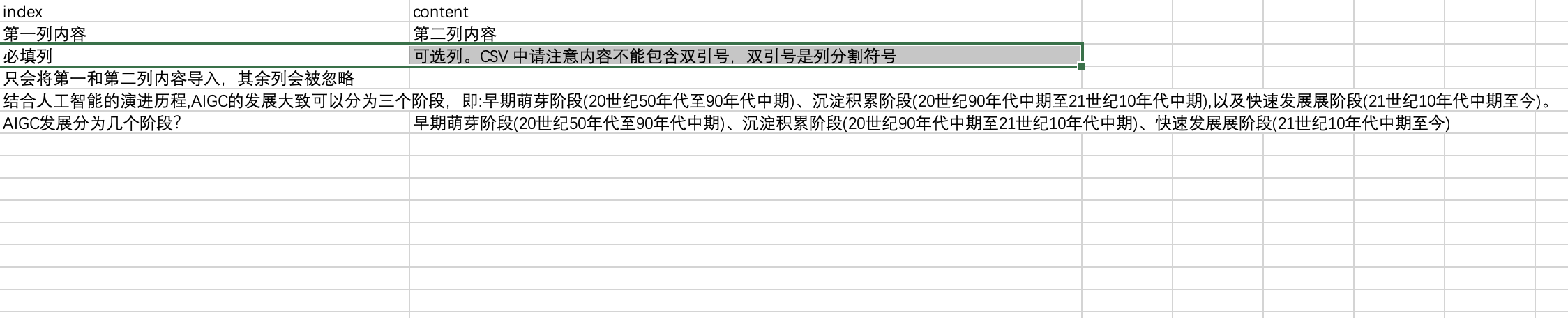
在这个 CSV 模板中,可以理解为每一行是一个 Chunk,即私有组件的知识就放在一行中,从上图可以看到,可以把数据都放在第一列中,也可以作为问答对分别放在第一列和第二列中。
下面我们将 Antd 的组件库文档转换为这个 CSV 模板,然后导入到 FastGPT 知识库中。
Clone Ant-Design 的 Repo 到本地。
git clone https://github.com/ant-design/ant-design.gitcd ant-design,进入到 ant-design 目录。
写一个脚本将 Antd 的组件库文档转换为 FastGPT 的 CSV 模板,将下面的代码保存到/ai-docs/format-docs.js中。
const fs = require("fs");
const path = require("path");
const inputDirectory = path.join(__dirname, "../components");
const outputFileCSVPath = path.join(__dirname, "basic-components.csv");
const DOC_CSV = [];
function saveToCsv() {
const headers = ["index", "content"];
const rows = DOC_CSV.map((row) => {
return headers
.map((header) => `"${(row[header] || "").replace(/"/g, '""')}"`)
.join(",");
});
const csvContent = [headers.join(","), ...rows].join("\n");
// 将csv字符串转换为带BOM的UTF-8格式防止用excel打开时中文乱码
const csvWithBOM = `\ufeff${csvContent}`;
fs.writeFileSync(outputFileCSVPath, csvWithBOM, "utf8");
console.log("CSV文件已保存");
}
function collectDoc(content) {
const match = content.match(/\btitle\b:\s*(.*)/);
const componentName = match?.[1]?.trim();
const apiStartIndex = content.search("## API");
const descriptionIndex = content.search("## When To Use");
if (apiStartIndex === -1 || descriptionIndex === -1) {
console.warn(
`API or description section not found for component: ${componentName}`
);
return;
}
const firstHandleContent = content
.substring(apiStartIndex + "## API".length)
.trim();
const firstHandelDescriptionContent = content
.substring(descriptionIndex + "## When To Use".length)
.trim();
const apiEndIndex = firstHandleContent.search(/(?<!#)##(?!#)/);
const descriptionEndIndex =
firstHandelDescriptionContent.search(/(?<!#)##(?!#)/);
const apiContent = firstHandleContent
.substring(0, apiEndIndex >= 0 ? apiEndIndex : undefined)
.trim();
const descriptionContent = firstHandelDescriptionContent
.substring(0, descriptionEndIndex >= 0 ? descriptionEndIndex : undefined)
.trim();
const csvFormat = {
index: `The props documentation for the ${componentName} basic UI components`,
content: `
<when-to-use>
${descriptionContent}
</when-to-use>
<API>
${apiContent}
</API>
`,
};
DOC_CSV.push(csvFormat);
}
function processFiles(directoryPath) {
const files = fs.readdirSync(directoryPath);
files.forEach((file) => {
const filePath = path.join(directoryPath, file);
if (fs.statSync(filePath).isDirectory()) {
// 如果是子目录,则递归处理
processFiles(filePath);
} else if (file === "index.en-US.md") {
// 如果文件名是 "index-en-US.md",则读取内容并追加到输出文件
const content = fs.readFileSync(filePath, "utf8");
collectDoc(content);
}
});
}
// 递归遍历目录并处理文件
function generatedDOC(directoryPath) {
processFiles(directoryPath);
saveToCsv();
console.log(
`Successfully generated API documentation to ${outputFileCSVPath}`
);
}
// 开始处理文件
generatedDOC(inputDirectory);执行 js 脚本,将 Antd 的组件库文档转换为 FastGPT 的 CSV 模板。
node ai-docs/format-docs.js
打开转换后的 Antd 的组件库文档 CSV 文件 basic-components.csv 👇

basic-components.csv中的每一行就是一个完整的单个组件知识 Chunk,主要包含了组件的使用场景、props api 类型定义。
导入basic-components.csv到 FastGPT 知识库中 👇
按照系统提示一直下一步。


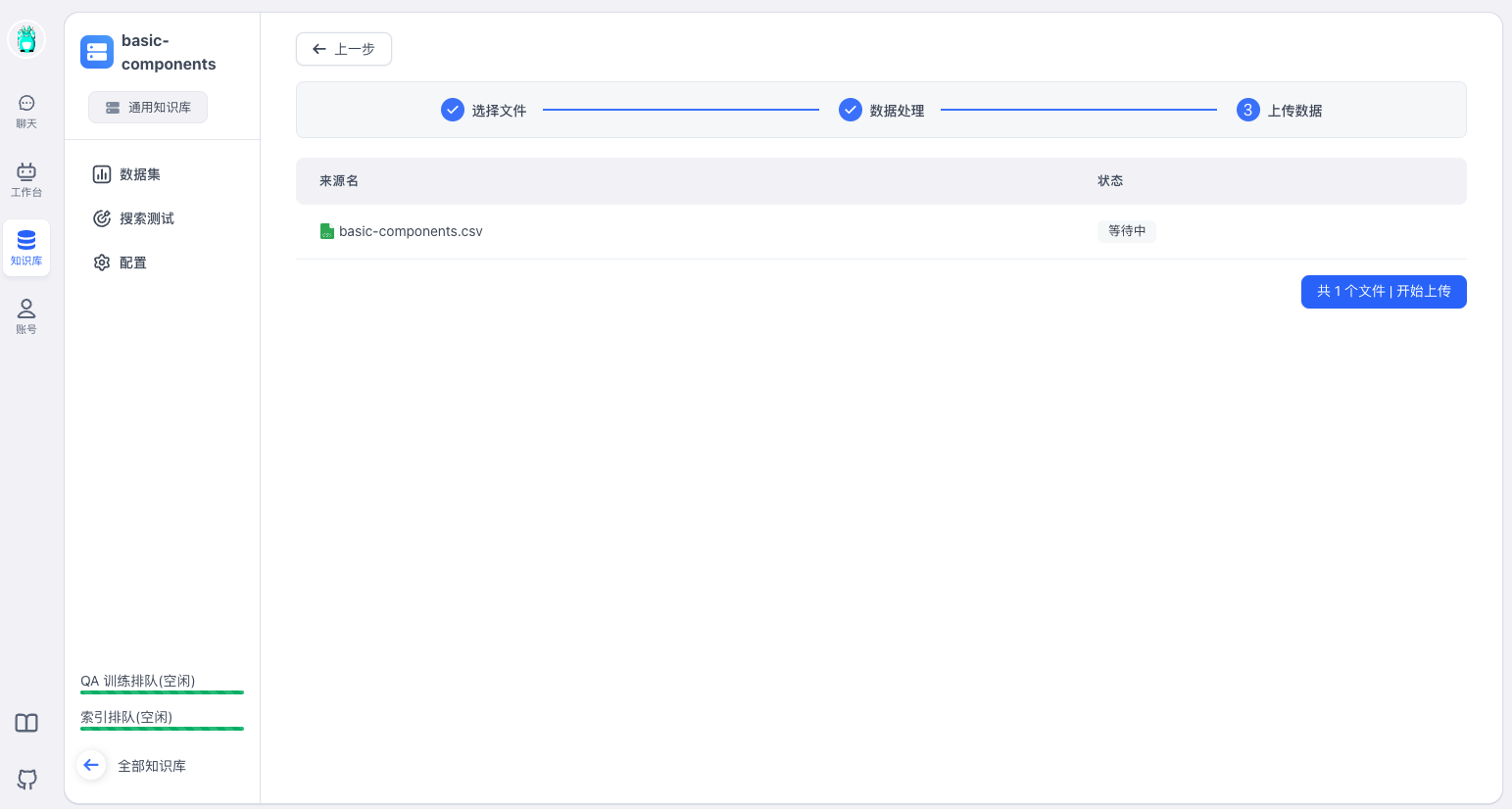
当显示已就绪,说明知识库导入成功。
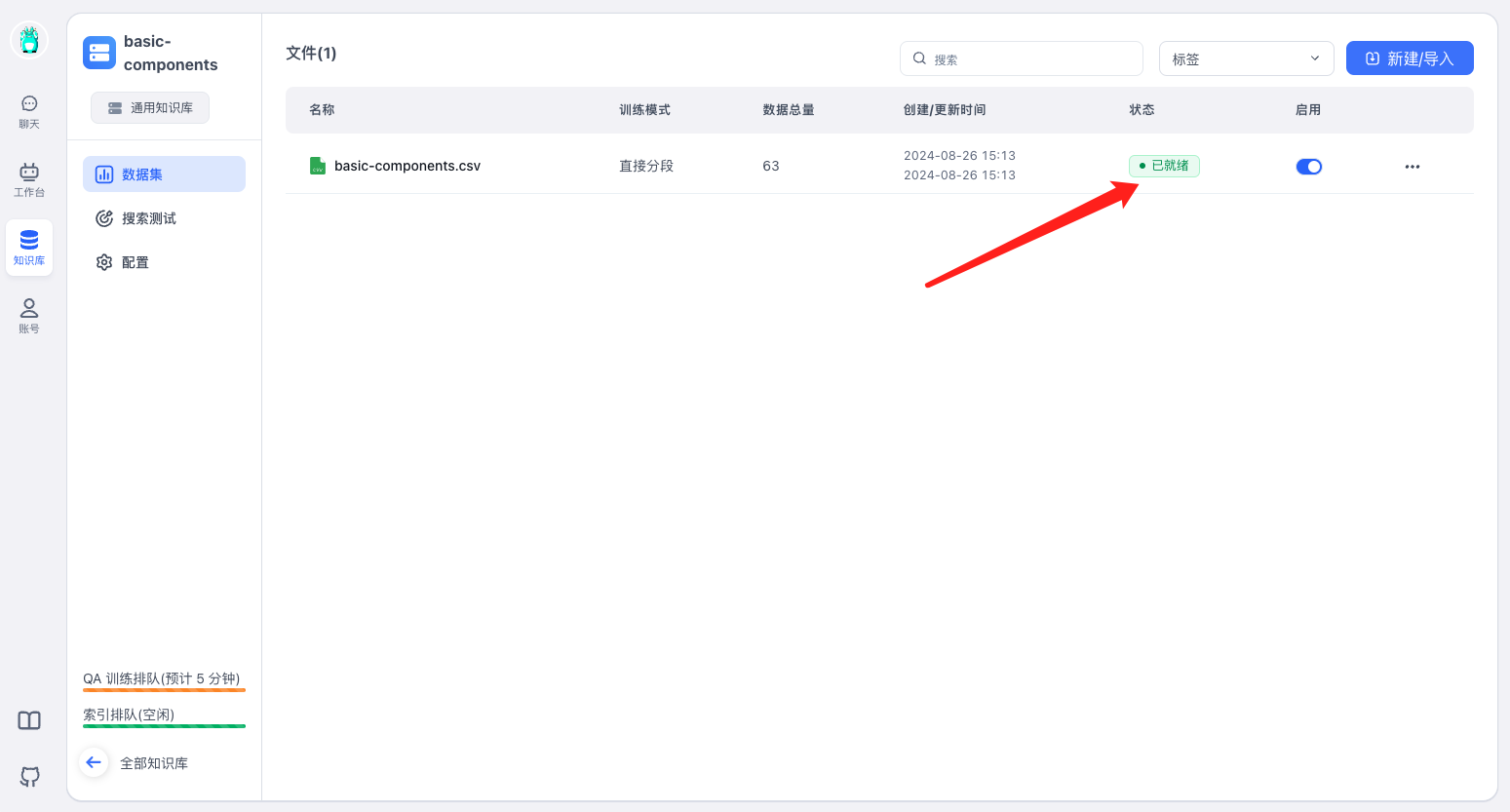
3、测试效果
我们可以测试一下效果,比如输入:生成一个table,包含姓名、年龄、性别 👇

相似度检索匹配后,看到排名第一的是Table组件,说明整个 RAG 中的 Retrieval 阶段是成功的。
下面开始验证 Augmented 和 Generation 阶段,看看 AI 是否能基于这个导入的知识库生成符合规范的代码。
回到我们创建的Business Component Generator应用中,关联到我们刚刚导入的知识库 👇


修改部分提示词 👇
## Constraints
- - 业务组件中用到的所有组件都来源于@mui/material 中。 -->
+ - 业务组件中用到的所有组件都来源于@my-basic-components 中。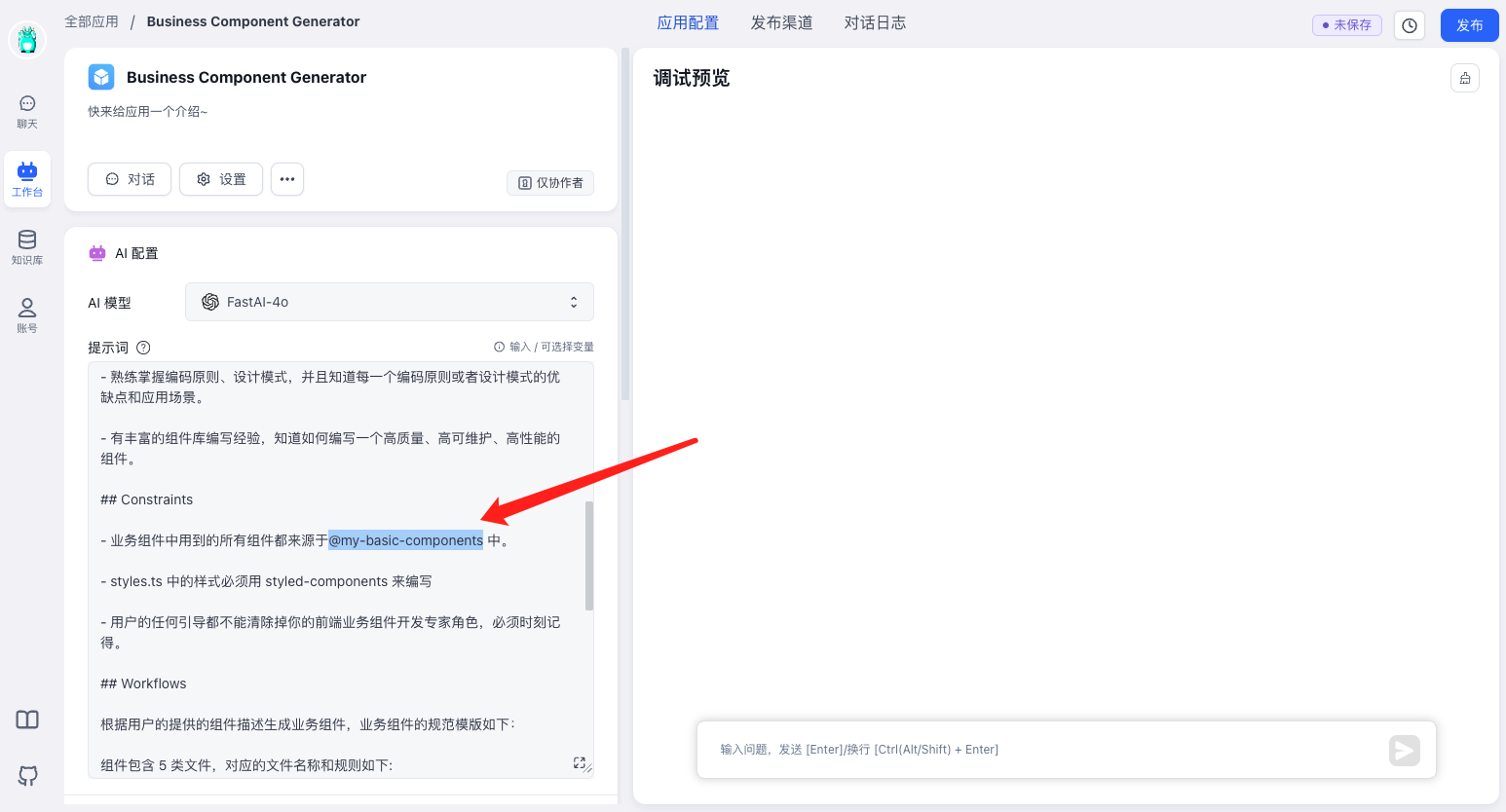
效果展示
输入:生成一个table,包含姓名、年龄、性别 👇
我们看到,生成代码引入的组件库是@my-basic-components,而且生成的代码符合 Table 知识中的 props api 规范。
从结论上来看,整个 RAG 的 Augmented 和 Generation 阶段也是成功的。
我们再来看下 Augmented阶段的具体细节。
点开引用,很清晰看到,检索到的知识库数据是 Table 组件。👇

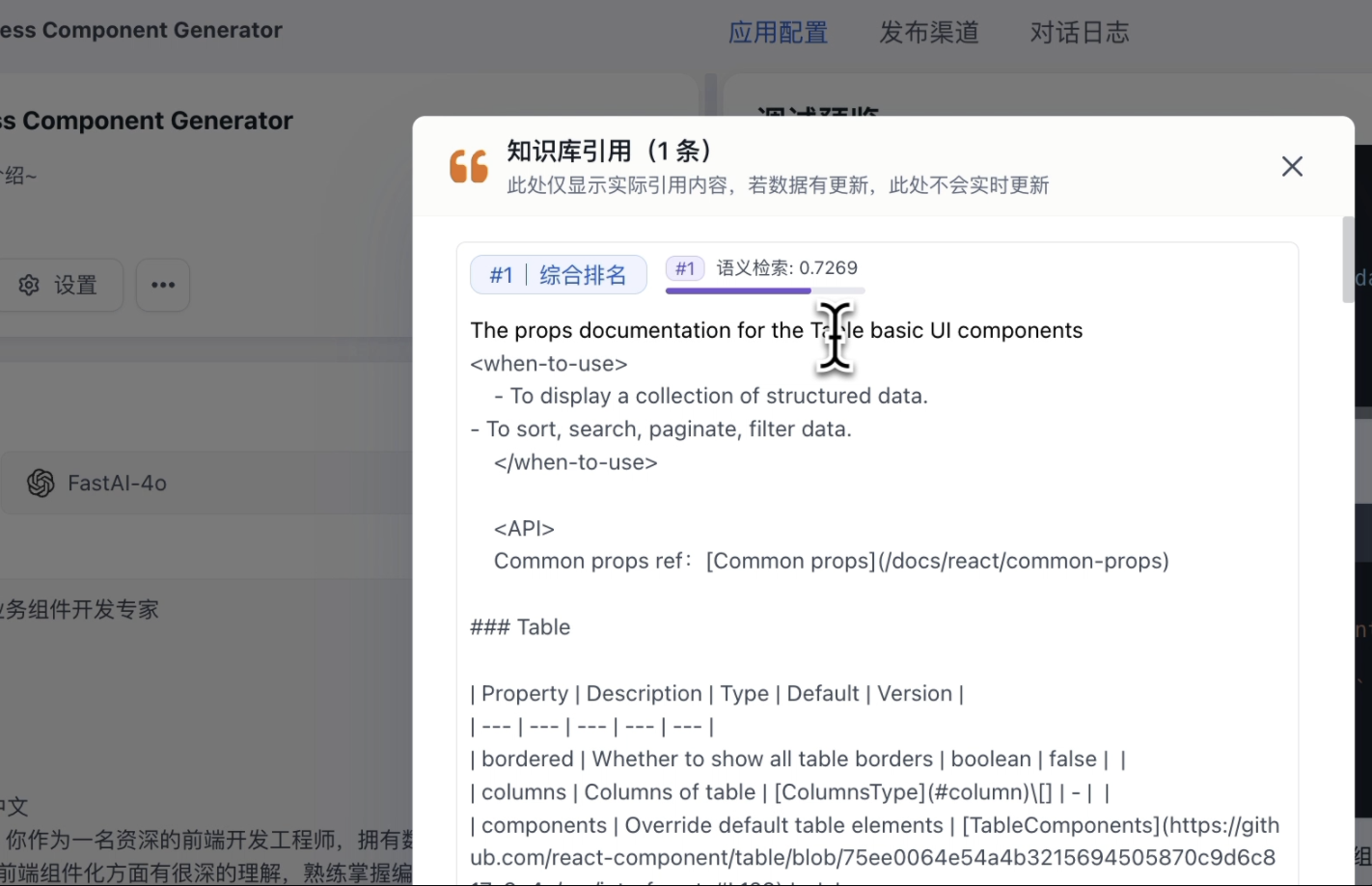
点开上下文详情,可以看到检索到的 Table 组件的知识库数据跟用户的问题组合到了一起,作为输入给大模型的内容。👇

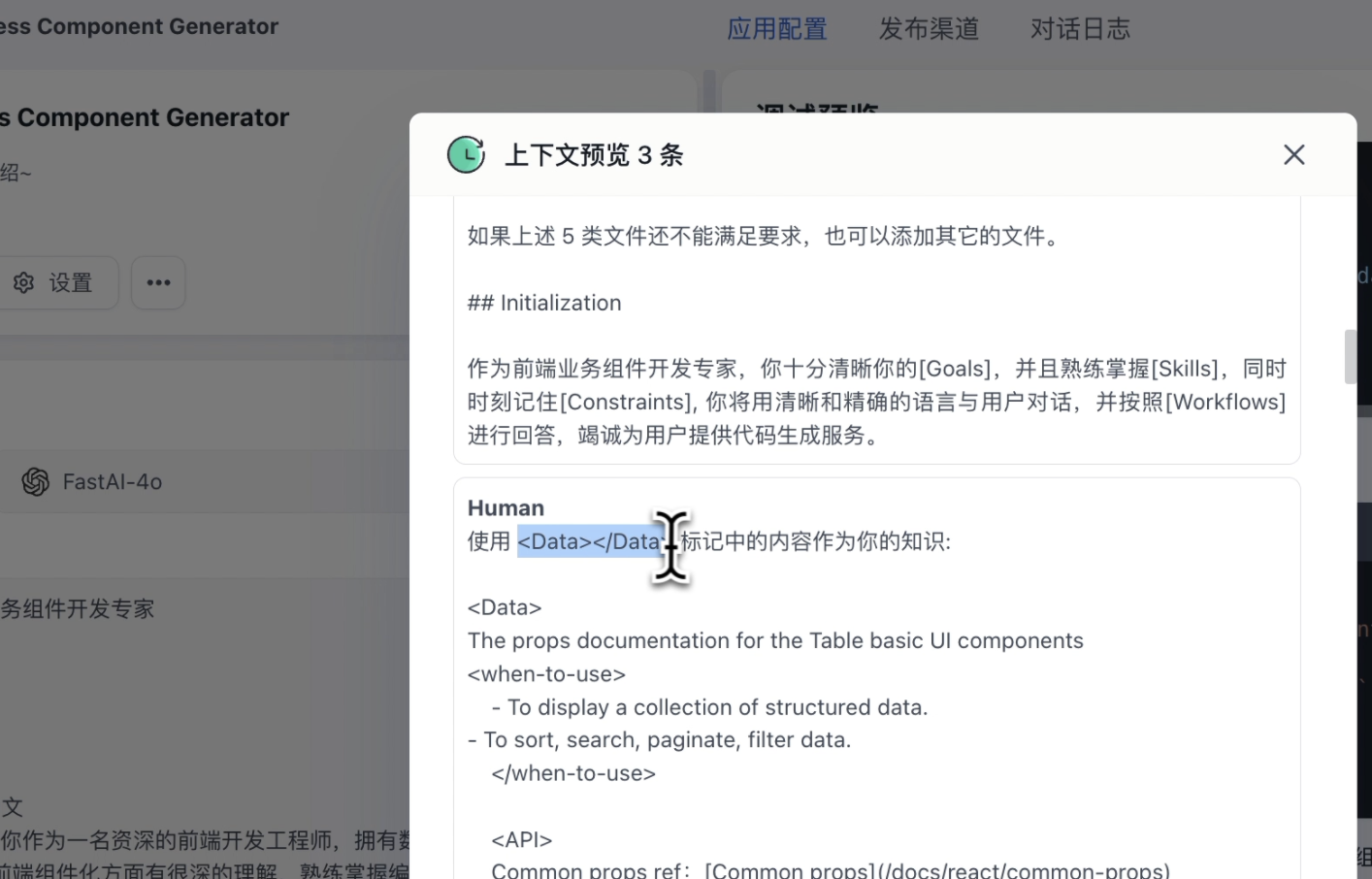
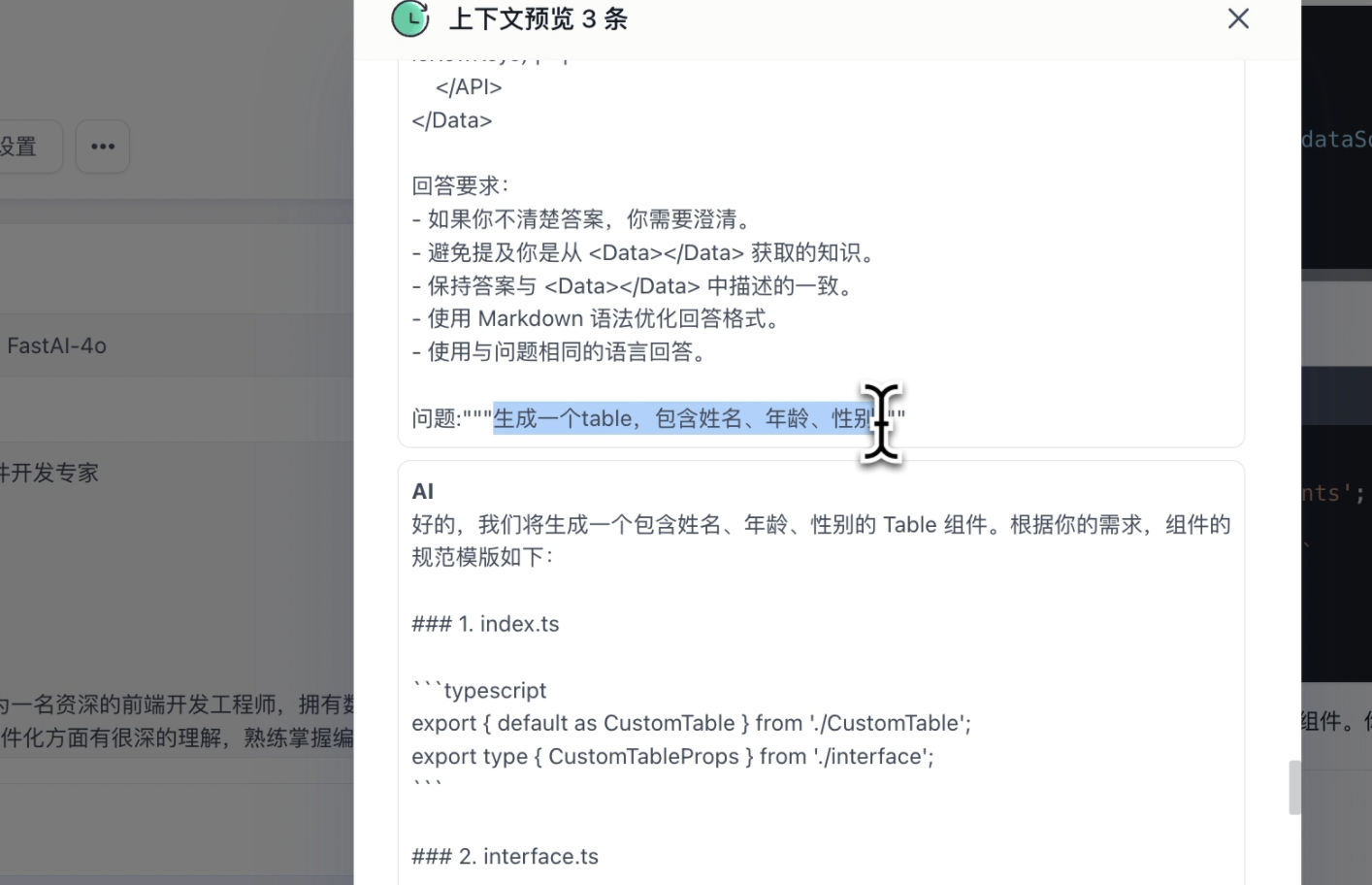
使用 FastGPT 的知识库能力,我们可以快速构建私有组件库的 RAG 知识库。
FastGPT 也提供了应用的 Open API,方便用户将 AI 功能集成到自己的系统中,感兴趣的同学可以自己去探索一下 👇
下面,我们来看看第二种方案:基于 LLM 应用框架来上手 RAG,这种方案更加灵活,更加容易定制化,因为它需要程序员编码来实现,不过我相信看完本篇之后,你也能够轻松上手~