方案三:自定义 AI Agent Workflow 接入私有组件库
在前面两个篇章中,我们分别介绍了FastGPT和LlamaIndex的私有组件库集成方案。
这两个方案中的 RAG Retrieval(检索)阶段,都是通过 Embedding 和 Vector Database 的语义检索方式来检索知识库数据。
让我们进一步思考,这种 Embedding 和 Vector Database 的语义检索方式是否能够很好的满足我们的需求?
问题一:RAG Retrieval 阶段采用 Embedding 和 Vector Database 的合理性
在「方案一:基于开源知识库平台接入私有组件库」我们新建的 FastGPT 应用中,我们来看 2 个示例:
示例 1: 输入生成一个登陆页面
我们发现,召回的知识库数据是App,其实我们所预期的知识库数据是Input、Button、Form等组件。
示例 2: 上传登陆界面的设计稿图,并生成代码。👇

同样的,召回的知识库数据并不是我们所预期的。
原因是什么?
本篇提到的 FastGPT 和 LlamaIndex 内部的 RAG Retrieval(检索)原理均采用 Embedding(嵌入)和 Vector Database(向量数据库)的方式,这种 Retrieval 的方式是基于语义相似度来进行。
因此,当用户提出的问题和知识库数据之间的语义相似度不高时,就会导致召回的知识库数据不准确。
上面的第一个示例中,用户提出的问题是生成一个登陆页面,而知识库数据中并没有登陆页面相关的知识数据,所以召回的数据不准确。
第二个示例中,用户上传的是登陆界面的设计稿图,而我们的私有组件库知识库是文本数据,两者的语义相似度很低,所以召回的数据也不准确。
那么,如何解决这个问题呢?
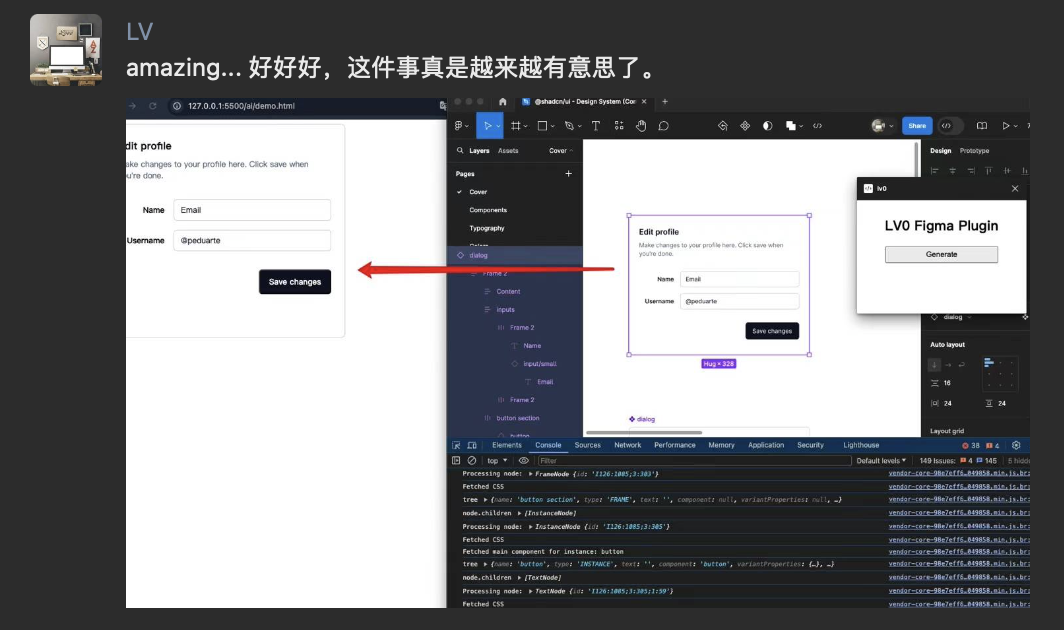
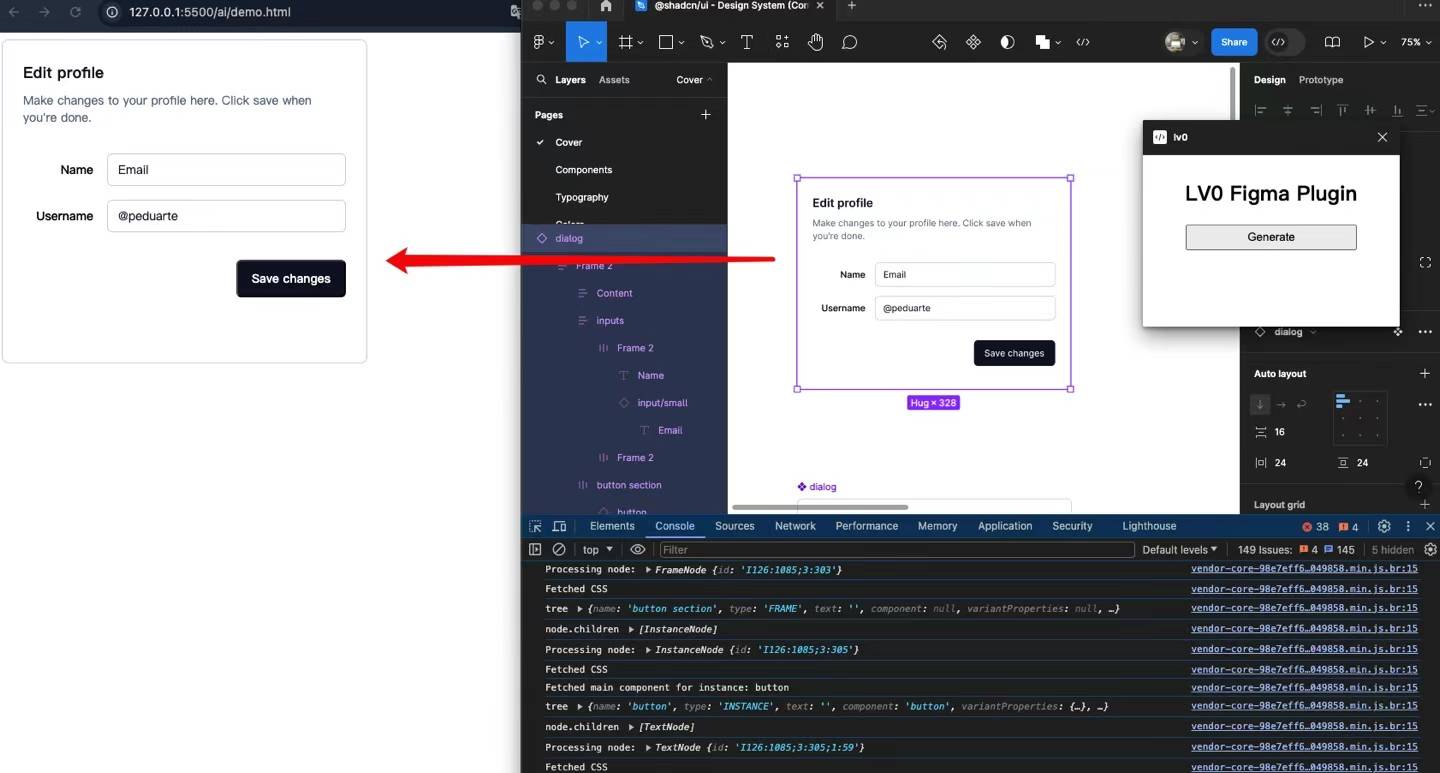
先看一下效果 👇
如上,在 LV0中,用户可以提供需求或者上传设计稿图, AI 会针对需求或者设计稿图分析出来所依赖的私有组件数据。
思路其实很简单:
1、将私有组件库每个组件的使用场景给到 AI,让 AI 根据用户的需求或者设计稿 + 组件使用场景来分析出来所依赖的私有组件名称列表。
2、遍历私有组件名称列表,key value 的形式从知识库中检索出来完整的组件知识数据。
问题二:基于自然语言和设计稿图生成代码在研发标准规范中的应用
在研发标准规范中,大致的产品研发流程如下:
业务需求 -> 产品设计 -> UI UX 设计 -> 前后端研发 -> 测试 -> 上线
从流程上看,作为前端研发,最重要的信息输入是UI UX 设计,即 UI 设计稿。
因此基于 UI 设计稿设计稿图生成代码(D2C)在标准的研发流程提效中是非常有意义的。
如果你尝试了让 AI 基于设计稿图片来生成代码,会发现如果是一些很简单的设计稿,生成的效果还是不错的。
一旦设计稿复杂度提高,以现阶段 AI 的能力,生成代码的 UI 还原度是很难保证的。
因此,基于设计稿图片来生成代码,或许不是现阶段最佳的解决方案。
那有没有更好的解决方案呢?
如果你公司用的是 Figma 等设计工具,建议可以考虑基于设计稿的原始数据来生成代码。
基于设计稿的原始数据,可以提取出组件的位置、大小、颜色、字体等信息,这些信息可以更好的帮助 AI 生成代码。
下一步计划
以上提到的两个问题,我们可以通过自定义 AI Agent Workflow来解决。
我计划通过视频课程的形式来更加详细讲解如何实现自定义 AI Agent Workflow。
点击关注,敬请期待!